Papers





The various fields associated with interactive software systems engage in design activities to enable people who would use the resulting systems to meet goals, coordinate with others, find meaning, and express themselves in myriad ways. Yet many development projects fail, and we all have contact with clumsy software-based systems that force work-arounds and impose substantial attentional, knowledge and workload burdens. On the other hand, field observations reveal people re-shaping the artifacts they encounter and interact with as resources to cope with the demands of the situations they face as they seek to meet their goals. In this process some new devices are quickly seized upon and exploited in ways that transform the nature of human activity, connections, and expression.
The software intensive interactive systems and devices under development around us are valuable to the degree that they expand what people in various roles and organizations can achieve. How can we measure this value provided to others? Are current measures of usability adequate? Does creeping complexity wipe out incremental gains as products evolve? Do designers and developers mis-project the impact when systems-to-be-realized are fielded? Which technology changes will trigger waves of expansive adaptations that transform what people do and even why they do it.
Sponsors of projects to develop new interactive software systems are asking developers for tangible evidence of the value to be delivered to those people responsible for activities and goals in the world. Traditional measures of usability and human performance seem inadequate. Cycles of inflation in the claims development organizations make (and the legacy of disappointment and surprise) have left sponsors numb and eroded trust. Thus, we need to provide new forms of evidence about the potential of new interactive systems and devices to enhance human capability.
Luckily, this need has been accompanied by a period of innovation in ways to measure the impact of new designs on:
This talk reviews a few of the new measures being tested in each of these categories, points to some of the underlying science, and uses these examples to trigger discussion about how design of future interactive software provides will provide value to stakeholders.

An effective user interface is a cooperative interaction between humans and their technology. For that interaction to work, it needs to recognize the limitations and exploit the strengths of both parties. In this talk, I will concentrate on the human side of the equation. What do we know about human visual perceptual abilities that might have an impact on the design of user interfaces? The world presents us with more information than we can process. Just try to read this abstract and the next piece of prose at the same time. We cope with this problem by using attentional mechanisms to select a subset of the input for further processing. An inter-face might be designed to .capture. attention, in order to induce a human to interact with it. Once the human is using an interface, that interface should .guide. the user.s atten-tion in an intelligent manner. In recent decades, many of the rules of attentional capture and guidance have been worked out in the laboratory. I will illustrate some of the basic principles. For example: Do some colors grab attention better than others? Are faces special? When and why do people fail to .see. things that are right in front of their eyes.

 3'05", 17Mb
3'05", 17Mb Studies of search habits reveal that people engage in many search tasks involving collaboration with others, such as travel planning, organizing social events, or working on a homework assignment. However, current Web search tools are designed for a single user, working alone. We introduce SearchTogether, a prototype that enables groups of remote users to synchronously or asynchronously collaborate when searching the Web. We describe an example usage scenario, and discuss the ways SearchTogether facilitates collaboration by supporting awareness, division of labor, and persistence. We then discuss the findings of our evaluation of SearchTogether, analyzing which aspects of its design enabled successful collaboration among study participants.

Programmers regularly use search as part of the development process, attempting to identify an appropriate API for a problem, seeking more information about an API, and seeking samples that show how to use an API. However, neither general-purpose search engines nor existing code search engines currently fit their needs, in large part because the information programmers need is distributed across many pages. We present Assieme, a Web search interface that effectively supports common programming search tasks by combining information from Web-accessible Java Archive (JAR) files, API documentation, and pages that include explanatory text and sample code. Assieme uses a novel approach to finding and resolving implicit references to Java packages, types, and members within sample code on the Web. In a study of programmers performing searches related to common programming tasks, we show that programmers obtain better solutions, using fewer queries, in the same amount of time spent using a general Web search interface.

Re-finding, a common Web task, is difficult when previously viewed information is modified, moved, or removed. For example, if a person finds a good result using the query "breast cancer treatments", she expects to be able to use the same query to locate the same result again. While re-finding could be supported by caching the original list, caching precludes the discovery of new information, such as, in this case, new treatment options. People often use search engines to simultaneously find and re-find information. The Re:Search Engine is designed to support both behaviors in dynamic environments like the Web by preserving only the memorable aspects of a result list. A study of result list memory shows that people forget a lot. The Re:Search Engine takes advantage of these memory lapses to include new results where old results have been forgotten.

Cameras are a useful source of input for many interactive applications, but computer vision programming is difficult and requires specialized knowledge that is out of reach for many HCI practitioners. In an effort to learn what makes a useful computer vision design tool, we created Eyepatch, a tool for designing camera-based interactions, and evaluated the Eyepatch prototype through deployment to students in an HCI course. This paper describes the lessons we learned about making computer vision more accessible, while retaining enough power and flexibility to be useful in a wide variety of interaction scenarios.
 6'08", 23Mb
6'08", 23Mb Recent research on handheld projector interaction has expanded the display and interaction space of handheld devices by projecting information onto the physical environment around the user, but has mainly focused on single-user scenarios. We extend this prior single-user research to co-located multi-user interaction using multiple handheld projectors. We present a set of interaction techniques for supporting co-located collaboration with multiple handheld projectors, and discuss application scenarios enabled by them.
 2'26", 9Mb
2'26", 9Mb We introduce Shadow Reaching, an interaction technique that makes use of a perspective projection applied to a shadow representation of a user. The technique was designed to facilitate manipulation over large distances and enhance understanding in collaborative settings. We describe three prototype implementations that illustrate the technique, examining the advantages of using shadows as an interaction metaphor to support single users and groups of collaborating users. Using these prototypes as a design probe, we discuss how the three components of the technique (sensing, modeling, and rendering) can be accomplished with real (physical) or computed (virtual) shadows, and the benefits and drawbacks of each approach.

A number of projects within the computer graphics, computer vision, and human-computer interaction communities have recognized the value of using projected structured light patterns for the purposes of doing range finding, location dependent data delivery, projector adaptation, or object discovery and tracking. However, most of the work exploring these concepts has relied on visible structured light patterns resulting in a caustic visual experience. In this work, we present the first design and implementation of a high-resolution, scalable, general purpose invisible near-infrared projector that can be manufactured in a practical manner. This approach is compatible with simultaneous visible light projection and integrates well with future Digital Light Processing (DLP) projector designs -- the most common type of projectors today. By unifying both the visible and non-visible pattern projection into a single device, we can greatly simply the implementation and execution of interactive projection systems. Additionally, we can inherently provide location discovery and tracking capabilities that are unattainable using other approaches.
 5'27", 18Mb
5'27", 18Mb We present three new interaction techniques for aiding users in collecting and organizing Web content. First, we demonstrate an interface for creating associations between websites, which facilitate the automatic retrieval of related content. Second, we present an authoring interface that allows users to quickly merge content from many different websites into a uniform and personalized representation, which we call a card. Finally, we introduce a novel search paradigm that leverages the relationships in a card to direct search queries to extract relevant content from multiple Web sources and fill a new series of cards instead of just returning a list of webpage URLs. Preliminary feedback from users is positive andvalidates our design.
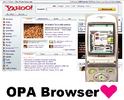 4'03", 40Mb
4'03", 40Mb Cellular phones are widely used to access the WWW. However, most available Web pages are designed for desktop PCs. Cellular phones only have small screens and poor interfaces, and thus, it is inconvenient to browse such large sized pages. In addition, cellular phone users browse Web pages in various situations, so that appropriate presentation styles for Web pages depend on users' situations. In this paper, we propose a novel Web browsing system for cellular phones that allocates various functions for Web browsing on each numerical key of a cellular phone. Users can browse Web pages comfortably, selecting appropriate functions according to their situations by pushing a single button.

We present a new web automation system that allows users to create a smart bookmark, consisting of a starting URL plus a script of commands that returns to a particular web page or state of a web application. A smart bookmark can be requested for any page, and the necessary commands are automatically extracted from the user's interaction history. Unlike other web macro recorders, which require the user to start recording before navigating to the desired page, smart bookmarks are generated retroactively, after the user has already reached a page, and the starting point of the macro is found automatically. Smart bookmarks have a rich graphical visualization that combines textual commands, web page screenshots, and animations to explain what the bookmark does. A bookmark's script consists of keyword commands, interpreted without strict reliance on syntax, allowing bookmarks to be easily edited and shared.
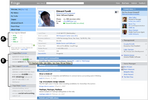
Employee directories play a valuable role in helping people find others to collaborate with, solve a problem, or provide needed expertise. Serving this role successfully requires accurate and up-to-date user profiles, yet few users take the time to maintain them. In this paper, we present a system that enables users to tag other users with key words that are displayed on their profiles. We discuss how people-tagging is a form of social bookmarking that enables people to organize their contacts into groups, annotate them with terms supporting future recall, and search for people by topic area. In addition, we show that people-tagging has a valuable side benefit: it enables the community to collectively maintain each others' interest and expertise profiles. Our user studies suggest that people tag other people as a form of contact management and that the tags they have been given are accurate descriptions of their interests and expertise. Moreover, none of the people interviewed reported offensive or inappropriate tags. Based on our results, we believe that peopletagging will become an important tool for relationship management in an organization.
 2'54", 13Mb
2'54", 13Mb Temporal events, while often discrete, also have interesting relationships within and across times: larger events are often collections of smaller more discrete events (battles within wars; artists' works within a form); events at one point also have correlations with events at other points (a play written in one period is related to its performance over a period of time). Most temporal visualisations, however, only represent discrete data points or single data types along a single timeline: this event started here and ended there; this work was published at this time; this tag was popular for this period. In order to represent richer, faceted attributes of temporal events, we present Continuum. Continuum enables hierarchical relationships in temporal data to be represented and explored; it enables relationships between events across periods to be expressed, and in particular it enables user-determined control over the level of detail of any facet of interest so that the person using the system can determine a focus point, no matter the level of zoom over the temporal space. We present the factors motivating our approach, our evaluation and implementation of this new visualisation which makes it easy for anyone to apply this interface to rich, large-scale datasets with temporal data.

Help-seeking communities have been playing an increasingly critical role in the way people seek and share information. However, traditional help-seeking mechanisms of these online communities have some limitations. In this paper, we describe an expertise-finding mechanism that attempts to alleviate the limitations caused by not knowing users' expertise levels. As a result of using social network data from the online community, this mechanism can automatically infer expertise level. This allows, for example, a question list to be personalized to the user's expertise level as well as to keyword similarity. We believe this expertise location mechanism will facilitate the development of next generation help-seeking communities.

Progress bars are prevalent in modern user interfaces. Typically, a linear function is employed such that the progress of the bar is directly proportional to how much work has been completed. However, numerous factors cause progress bars to proceed at non-linear rates. Additionally, humans perceive time in a non-linear way. This paper explores the impact of various progress bar behaviors on user perception of process duration. The results are used to suggest several design considerations that can make progress bars appear faster and ultimately improve users' computing experience.
 5'57", 21Mb
5'57", 21Mb SketchWizard allows designers to create Wizard of Oz prototypes of pen-based user interfaces in the early stages of design. In the past, designers have been inhibited from participating in the design of pen-based interfaces because of the inadequacy of paper prototypes and the difficulty of developing functional prototypes. In SketchWizard, designers and end users share a drawing canvas between two computers, allowing the designer to simulate the behavior of recognition or other technologies. Special editing features are provided to help designers respond quickly to end-user input. This paper describes the SketchWizard system and presents two evaluations of our approach. The first is an early feasibility study in which Wizard of Oz was used to prototype a pen-based user interface. The second is a laboratory study in which designers used SketchWizard to simulate existing pen-based interfaces. Both showed that end users gave valuable feedback in spite of delays between end-user actions and wizard updates.
 1'12", 9Mb
1'12", 9Mb Position control devices enable precise selection, but significant clutching degrades performance. Clutching can be reduced with high control-display gain or pointer acceleration, but there are human and device limits. Elastic rate control eliminates clutching completely, but can make precise selection difficult. We show that hybrid position-rate control can outperform position control by 20% when there is significant clutching, even when using pointer acceleration. Unlike previous work, our RubberEdge technique eliminates trajectory and velocity discontinuities. We derive predictive models for position control with clutching and hybrid control, and present a prototype RubberEdge position-rate control device including initial user feedback.

Webmail clients provide millions of end users with convenient and ubiquitous access to electronic mail - the most successful collaboration tool ever. Web email clients are also the platform of choice for recent innovations on electronic mail and for integration of related information services into email. In the enterprise, however, webmail applications have been relegated to being a supplemental tool for mail access from home or while on the road. In this paper, we draw on recent research in the area of electronic mail to understand usage models and performance requirements for enterprise email applications. We then present an innovative architecture for a webmail client. By leveraging recent advances in web browser technology, we show that webmail clients can offer performance and responsiveness that rivals a desktop application while still retaining all the advantages of a browser based client.

In this paper, we present a methodology for recognizing seatedpostures using data from pressure sensors installed on a chair.Information about seated postures could be used to help avoidadverse effects of sitting for long periods of time or to predictseated activities for a human-computer interface. Our system designdisplays accurate near-real-time classification performance on datafrom subjects on which the posture recognition system was nottrained by using a set of carefully designed, subject-invariantsignal features. By using a near-optimal sensor placement strategy,we keep the number of required sensors low thereby reducing costand computational complexity. We evaluated the performance of ourtechnology using a series of empirical methods including (1)cross-validation (classification accuracy of 87% for ten posturesusing data from 31 sensors), and (2) a physical deployment of oursystem (78% classification accuracy using data from 19sensors).

Although mobile, tablet, large display, and tabletop computers increasingly present opportunities for using pen, finger, and wand gestures in user interfaces, implementing gesture recognition largely has been the privilege of pattern matching experts, not user interface prototypers. Although some user interface libraries and toolkits offer gesture recognizers, such infrastructure is often unavailable in design-oriented environments like Flash, scripting environments like JavaScript, or brand new off-desktop prototyping environments. To enable novice programmers to incorporate gestures into their UI prototypes, we present a "$1 recognizer" that is easy, cheap, and usable almost anywhere in about 100 lines of code. In a study comparing our $1 recognizer, Dynamic Time Warping, and the Rubine classifier on user-supplied gestures, we found that $1 obtains over 97% accuracy with only 1 loaded template and 99% accuracy with 3+ loaded templates. These results were nearly identical to DTW and superior to Rubine. In addition, we found that medium-speed gestures, in which users balanced speed and accuracy, were recognized better than slow or fast gestures for all three recognizers. We also discuss the effect that the number of templates or training examples has on recognition, the score falloff along recognizers' N-best lists, and results for individual gestures. We include detailed pseudocode of the $1 recognizer to aid development, inspection, extension, and testing.
 1'59", 10Mb
1'59", 10Mb Most current implementations of multi-touch screens are still too expensive or too bulky for widespread adoption. To improve this situation, this work describes the electronics and software needed to collect more data than one pair of coordinates from a standard 4-wire touch screen. With this system, one can measure the pressure of a single touch and approximately sense the coordinates of two touches occurring simultaneously. Naturally, the system cannot offer the accuracy and versatility of full multi-touch screens. Nonetheless, several example applications ranging from painting to zooming demonstrate a broad spectrum of use.
 4'59", 10Mb
4'59", 10Mb Spatial layout is frequently used for managing loosely organized information, such as desktop icons and digital ink. To help users organize this type of information efficiently, we propose an interface for manipulating spatial aggregations of objects. The aggregated objects are automatically recognized as a group, and the group structure is visualized as a two-dimensional bubble surface that surrounds the objects. Users can drag, copy, or delete a group by operating on the bubble. Furthermore, to help pick out individual objects in a dense aggregation, the system spreads the objects to avoid overlapping when requested. This paper describes the design of this interface and its implementation. We tested our technique in icon grouping and ink relocation tasks and observed improvements in user performance.

A common task in graphical user interfaces is controlling onscreen elements using a pointer. Current adaptive pointing techniques require applications to be built using accessibility libraries that reveal information about interactive targets, and most do not handle path/menu navigation. We present a pseudo-haptic technique that is OS and application independent, and can handle both dragging and clicking. We do this by associating a small force with each past click or drag. When a user frequently clicks in the same general area (e.g., on a button), the patina of past clicks naturally creates a pseudo-haptic magnetic field with an effect similar to that ofsnapping or sticky icons. Our contribution is a bottom-up approach to make targets easier to select without requiring prior knowledge of them.
 5'00", 13Mb
5'00", 13Mb We present the boomerang technique, which makes it possible to suspend and resume drag-and-drop operations. A throwing gesture while dragging an object suspends the operation, anytime and anywhere. A drag-and-drop interaction, enhanced with our technique, allows users to switch windows, invoke commands, and even drag other objects during a drag-and-drop operation without using the keyboard or menus. We explain how a throwing gesture can suspend drag-and-drop operations, and describe other features of our technique, including grouping, copying, and deleting dragged objects. We conclude by presenting prototype implementations and initial feedback on the proposed technique.
 2'27", 13Mb
2'27", 13Mb Information cannot be found if it is not recorded. Existing rich graphical application approaches interfere with user input in many ways, forcing complex interactions to enter simple information, requiring complex cognition to decide where the data should be stored, and limiting the kind of information that can be entered to what can fit into specific applications' data models. Freeform text entry suffers from none of these limitations but produces data that is hard to retrieve or visualize. We describe the design and implementation of Jourknow, a system that aims to bridge these two modalities, supporting lightweight text entry and weightless context capture that produces enough structure to support rich interactive presentation and retrieval of the arbitrary information entered.

We explore the use of abstracted screenshots as part of a new help interface. Graphstract, an implementation of a graphical help system, extends the ideas of textually oriented Minimal Manuals to the use of screenshots, allowing multiple small graphical elements to be shown in a limited space. This allows a user to get an overview of a complex sequential task as a whole. The ideas have been developed by three iterations of prototyping and evaluation. A user study shows that Graphstract helps users perform tasks faster on some but not all tasks. Due to their graphical nature, it is possible to construct Graphstracts automatically from pre-recorded interactions. A second study shows that automated capture and replay is a low-cost method for authoring Graphstracts, and the resultant help is as understandable as manually constructed help.
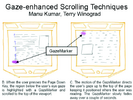
Scrolling is an essential part of our everyday computing experience. Contemporary scrolling techniques rely on the explicit initiation of scrolling by the user. The act of scrolling is tightly coupled with the user?s ability to absorb information via the visual channel. The use of eye gaze information is therefore a natural choice for enhancing scrolling techniques. We present several gaze-enhanced scrolling techniques for manual and automatic scrolling which use gaze information as a primary input or as an augmented input. We also introduce the use off-screen gaze-actuated buttons for document navigation and control.
 2'12", 15Mb
2'12", 15Mb We describe a unique form of hands-free interaction that can be implemented on most commodity computing platforms. Our approach supports blowing at a laptop or computer screen to directly control certain interactive applications. Localization estimates are produced in real-time to determine where on the screen the person is blowing. Our approach relies solely on a single microphone, such as those already embedded in a standard laptop or one placed near a computer monitor, which makes our approach very cost-effective and easy-to-deploy. We show example interaction techniques that leverage this approach.

Creating high-quality label layouts in a particular visual style is a time-consuming process. Although automated labeling algorithms can aid the layout process, expert design knowledge is required to tune these algorithms so that they produce layouts which meet the designer's expectations. We propose a system which can learn a labellayout style from a single example layout and then apply this style to new labeling problems. Because designers find it much easier to create example layouts than tune algorithmic parameters, our system provides a more natural workflow for graphic designers. We demonstrate that our system is capable of learning a variety of label layout styles from examples.

Most of today's GUIs are designed for the typical, able-bodied user; atypical users are, for the most part, left to adapt as best they can, perhaps using specialized assistive technologies as an aid. In this paper, we present an alternative approach: SUPPLE++ automatically generates interfaces which are tailored to an individual's motor capabilities and can be easily adjusted to accommodate varying vision capabilities. SUPPLE++ models users. motor capabilities based on a onetime motor performance test and uses this model in an optimization process, generating a personalized interface. A preliminary study indicates that while there is still room for improvement, SUPPLE++ allowed one user to complete tasks that she could not perform using a standard interface, while for the remaining users it resulted in an average time savings of 20%, ranging from an slowdown of 3% to a speedup of 43%.
 3'43", 29Mb
3'43", 29Mb Source-code examples of APIs enable developers to quickly gain a gestalt understanding of a library's functionality, and they support organically creating applications by incrementally modifying a functional starting point. As an increasing number of web sites provide APIs, significantlatent value lies in connecting the complementary representations between site and service - in essence, enabling sites themselves to be the example corpus. We introduce d.mix, a tool for creating web mashups that leverages this site-to-service correspondence. With d.mix, users browse annotated web sites and select elements to sample. d.mix's sampling mechanism generates the underlying service calls that yield those elements. This code can be edited, executed, and shared in d.mix's wiki-based hosting environment. This sampling approach leverages pre-existing web sites as example sets and supports fluid composition and modification of examples. An initial study with eight participants found d.mix to enable rapid experimentation, and suggested avenues for improving its annotation mechanism.

The development of user interface systems has languished with the stability of desktop computing. Future systems, however, that are off-the-desktop, nomadic or physical in nature will involve new devices and new software systems for creating interactive applications. Simple usability testing is not adequate for evaluating complex systems. The problems with evaluating systems work are explored and a set of criteria for evaluating new UI systems work is presented.

ThinSight is a novel optical sensing system, fully integrated into a thin form factor display, capable of detecting multi-ple fingers placed on or near the display surface. We describe this new hardware in detail, and demonstrate how it can be embedded behind a regular LCD, allowing sensing without degradation of display capability. With our approach, fingertips and hands are clearly identifiable through the display. The approach of optical sensing also opens up the exciting possibility for detecting other physical objects and visual markers through the display, and some initial experiments are described. We also discuss other novel capabilities of our system: interaction at a distance using IR pointing devices, and IR-based communication with other electronic devices through the display. A major advantage of ThinSight over existing camera and projector based optical systems is its compact, thin form-factor making such systems even more deployable. We therefore envisage using ThinSight to capture rich sensor data through the display which can be processed using computer vision techniques to enable both multi-touch and tangible interaction.
 3'27", 22Mb
3'27", 22Mb Touch is a compelling input modality for interactive devices; however, touch input on the small screen of a mobile device is problematic because a user's fingers occlude the graphical elements he wishes to work with. In this paper, we present LucidTouch, a mobile device that addresses this limitation by allowing the user to control the application by touching the back of the device. The key to making this usable is what we call pseudo-transparency: by overlaying an image of the user's hands onto the screen, we create the illusion of the mobile device itself being semi-transparent. This pseudo-transparency allows users to accurately acquire targets while not occluding the screen with their fingers and hand. Lucid Touch also supports multi-touch input, allowing users to operate the device simultaneously with all 10 fingers. We present initial study results that indicate that many users found touching on the back to be preferable to touching on the front, due to reduced occlusion, higher precision, and the ability to make multi-finger input.
 3'14", 38Mb
3'14", 38Mb Multi-display environments compose displays that can be at different locations from and different angles to the user; as a result, it can become very difficult to manage windows, read text, and manipulate objects. We investigate the idea of perspective as a way to solve these problems in multi-display environments. We first identify basic display and control factors that are affected by perspective, such as visibility, fracture, and sharing. We then present the design and implementation of E-conic, a multi-display multi-user environment that uses location data about displays and users to dynamically correct perspective. We carried out a controlled experiment to test the benefits of perspective correction in basic interaction tasks like targeting, steering, aligning, pattern-matching and reading. Our results show that perspective correction significantly and substantially improves user performance in all these tasks.




