Keywords






Interaction with large unstructured datasets is difficult because existing approaches, such as keyword search, are not always suited to describing concepts corresponding to the distinctions people want to make within datasets. One possible solution is to allow end users to train machine learning systems to identify desired concepts, a strategy known as interactive concept learning. A fundamental challenge is to design systems that preserve end user flexibility and control while also guiding them to provide examples that allow the machine learning system to effectively learn the desired concept. This paper presents our design and evaluation of four new overview based approaches to guiding example selection. We situate our explorations within CueFlik, a system examining end user interactive concept learning in Web image search. Our evaluation shows our approaches not only guide end users to select better training examples than the best performing previous design for this application, but also reduce the impact of not knowing when to stop training the system. We discuss challenges for end user interactive concept learning systems and identify opportunities for future research on the effective design of such systems.

 3'41", 21Mb
3'41", 21Mb Modern computer displays tend to be in fixed size, rigid, and rectilinear rendering them insensitive to the visual area demands of an application or the desires of the user. Foldable displays offer the ability to reshape and resize the interactive surface at our convenience and even permit us to carry a very large display surface in a small volume. In this paper, we implement four interactive foldable display designs using image projection with low-cost tracking and explore display behaviors using orientation sensitivity.


 6'10", 147Mb
6'10", 147Mb 



 3'41", 23Mb
3'41", 23Mb  2'13", 71Mb
2'13", 71Mb Tabletop applications cannot display more than a few dozen on-screen objects. The reason is their limited size: tables cannot become larger than arm's length without giving up direct touch. We propose creating direct touch surfaces that are orders of magnitude larger. We approach this challenge by integrating high-resolution multitouch input into a back-projected floor. As the same time, we maintain the purpose and interaction concepts of tabletop computers, namely direct manipulation.
We base our hardware design on frustrated total internal reflection. Its ability to sense per-pixel pressure allows the floor to locate and analyze users' soles. We demonstrate how this allows the floor to recognize foot postures and identify users. These two functions form the basis of our system. They allow the floor to ignore users unless they interact explicitly, identify and track users based on their shoes, enable high-precision interaction, invoke menus, track heads, and allow users to control high-degree of freedom interactions using their feet. While we base our designs on a series of simple user studies, the primary contribution on this paper is in the engineering domain.



 3'03", 10Mb
3'03", 10Mb 
 4'18", 74Mb
4'18", 74Mb  4'52", 32Mb
4'52", 32Mb  4'36", 85Mb
4'36", 85Mb We introduce TwinSpace, a flexible software infrastructure for combining interactive workspaces and collaborative virtual worlds. Its design is grounded in the need to support deep connectivity and flexible mappings between virtual and real spaces to effectively support collaboration. This is achieved through a robust connectivity layer linking heterogeneous collections of physical and virtual devices and services, and a centralized service to manage and control mappings between physical and virtual. In this paper we motivate and present the architecture of TwinSpace, discuss our experiences and lessons learned in building a generic framework for collaborative cross-reality, and illustrate the architecture using two implemented examples that highlight its flexibility and range, and its support for rapid prototyping.

The various fields associated with interactive software systems engage in design activities to enable people who would use the resulting systems to meet goals, coordinate with others, find meaning, and express themselves in myriad ways. Yet many development projects fail, and we all have contact with clumsy software-based systems that force work-arounds and impose substantial attentional, knowledge and workload burdens. On the other hand, field observations reveal people re-shaping the artifacts they encounter and interact with as resources to cope with the demands of the situations they face as they seek to meet their goals. In this process some new devices are quickly seized upon and exploited in ways that transform the nature of human activity, connections, and expression.
The software intensive interactive systems and devices under development around us are valuable to the degree that they expand what people in various roles and organizations can achieve. How can we measure this value provided to others? Are current measures of usability adequate? Does creeping complexity wipe out incremental gains as products evolve? Do designers and developers mis-project the impact when systems-to-be-realized are fielded? Which technology changes will trigger waves of expansive adaptations that transform what people do and even why they do it.
Sponsors of projects to develop new interactive software systems are asking developers for tangible evidence of the value to be delivered to those people responsible for activities and goals in the world. Traditional measures of usability and human performance seem inadequate. Cycles of inflation in the claims development organizations make (and the legacy of disappointment and surprise) have left sponsors numb and eroded trust. Thus, we need to provide new forms of evidence about the potential of new interactive systems and devices to enhance human capability.
Luckily, this need has been accompanied by a period of innovation in ways to measure the impact of new designs on:
This talk reviews a few of the new measures being tested in each of these categories, points to some of the underlying science, and uses these examples to trigger discussion about how design of future interactive software provides will provide value to stakeholders.
 4'56", 42Mb
4'56", 42Mb Instrumented with multiple depth cameras and projectors, LightSpace is a small room installation designed to explore a variety of interactions and computational strategies related to interactive displays and the space that they inhabit. LightSpace cameras and projectors are calibrated to 3D real world coordinates, allowing for projection of graphics correctly onto any surface visible by both camera and projector. Selective projection of the depth camera data enables emulation of interactive displays on un-instrumented surfaces (such as a standard table or office desk), as well as facilitates mid-air interactions between and around these displays. For example, after performing multi-touch interactions on a virtual object on the tabletop, the user may transfer the object to another display by simultaneously touching the object and the destination display. Or the user may "pick up" the object by sweeping it into their hand, see it sitting in their hand as they walk over to an interactive wall display, and "drop" the object onto the wall by touching it with their other hand. We detail the interactions and algorithms unique to LightSpace, discuss some initial observations of use and suggest future directions.
 3'57", 23Mb
3'57", 23Mb  3'41", 27Mb
3'41", 27Mb  5'08", 45Mb
5'08", 45Mb This paper explores the intersection of emerging surface technologies, capable of sensing multiple contacts and of-ten shape information, and advanced games physics engines. We define a technique for modeling the data sensed from such surfaces as input within a physics simulation. This affords the user the ability to interact with digital objects in ways analogous to manipulation of real objects. Our technique is capable of modeling both multiple contact points and more sophisticated shape information, such as the entire hand or other physical objects, and of mapping this user input to contact forces due to friction and collisions within the physics simulation. This enables a variety of fine-grained and casual interactions, supporting finger-based, whole-hand, and tangible input. We demonstrate how our technique can be used to add real-world dynamics to interactive surfaces such as a vision-based tabletop, creating a fluid and natural experience. Our approach hides from application developers many of the complexities inherent in using physics engines, allowing the creation of applications without preprogrammed interaction behavior or gesture recognition.
 3'45", 16Mb
3'45", 16Mb We show how to design touchscreen widgets that respond to a finger's contact area. In standard touchscreen systems a finger often appears to touch several screen objects, but the system responds as though only a single pixel is touched. In contact area interaction all objects under the finger respond to the touch. Users activate control widgets by sliding a movable element, as though flipping a switch. These Sliding Widgets resolve selection ambiguity and provide designers with a rich vocabulary of self-disclosing interaction mechanism. We showcase the design of several types of Sliding Widgets, and report study results showing that the simplest of these widgets, the Sliding Button, performs on-par with medium-sized pushbuttons and offers greater accuracy for small-sized buttons.

PhotoelasticTouch is a novel tabletop system designed to intuitively facilitate touch-based interaction via real objects made from transparent elastic material. The system utilizes vision-based recognition techniques and the photoelastic properties of the transparent rubber to recognize deformed regions of the elastic material. Our system works with elastic materials over a wide variety of shapes and does not require any explicit visual markers. Compared to traditional interactive surfaces, our 2.5 dimensional interface system enables direct touch interaction and soft tactile feedback. In this paper we present our force sensing technique using photoelasticity and describe the implementation of our prototype system. We also present three practical applications of PhotoelasticTouch, a force-sensitive touch panel, a tangible face application, and a paint application.
 4'09", 48Mb
4'09", 48Mb Although interactive surfaces have many unique and compelling qualities, the interactions they support are by their very nature bound to the display surface. In this paper we present a technique for users to seamlessly switch between interacting on the tabletop surface to above it. Our aim is to leverage the space above the surface in combination with the regular tabletop display to allow more intuitive manipulation of digital content in three-dimensions. Our goal is to design a technique that closely resembles the ways we manipulate physical objects in the real-world; conceptually, allowing virtual objects to be 'picked up' off the tabletop surface in order to manipulate their three dimensional position or orientation. We chart the evolution of this technique, implemented on two rear projection-vision tabletops. Both use special projection screen materials to allow sensing at significant depths beyond the display. Existing and new computer vision techniques are used to sense hand gestures and postures above the tabletop, which can be used alongside more familiar multi-touch interactions. Interacting above the surface in this way opens up many interesting challenges. In particular it breaks the direct interaction metaphor that most tabletops afford. We present a novel shadow-based technique to help alleviate this issue. We discuss the strengths and limitations of our technique based on our own observations and initial user feedback, and provide various insights from comparing, and contrasting, our tabletop implementations

 2'09", 11Mb
2'09", 11Mb  3'13", 50Mb
3'13", 50Mb This note examines the role traditional input devices can play in surface computing. Mice and keyboards can enhance tabletop technologies since they support high fidelity input, facilitate interaction with distant objects, and serve as a proxy for user identity and position. Interactive tabletops, in turn, can enhance the functionality of traditional input devices: they provide spatial sensing, augment devices with co-located visual content, and support connections among a plurality of devices. We introduce eight interaction techniques for a table with mice and keyboards, and we discuss the design space of such interactions.
 3'31", 19Mb
3'31", 19Mb PhoneTouch is a novel technique for integration of mobile phones and interactive surfaces. The technique enables use of phones to select targets on the surface by direct touch, facilitating for instance pick&drop-style transfer of objects between phone and surface. The technique is based on separate detection of phone touch events by the surface, which determines location of the touch, and by the phone, which contributes device identity. The device-level observations are merged based on correlation in time. We describe a proof-of-concept implementation of the technique, using vision for touch detection on the surface (including discrimination of finger versus phone touch) and acceleration features for detection by the phone.

Efficiently entering text on interactive surfaces, such as touch-based tabletops, is an important concern. One novel solution is shape writing - the user strokes through all the letters in the word on a virtual keyboard without lifting his or her finger. While this technique can be used with any keyboard layout, the layout does impact the expected performance. In this paper, I investigate the influence of keyboard layout on expert text-entry performance for stroke-based text entry. Based on empirical data, I create a model of stroking through a series of points based on Fitts's law. I then use that model to evaluate various keyboard layouts for both tapping and stroking input. While the stroke-based technique seems promising by itself (i.e., there is a predicted gain of 17.3% for a Qwerty layout), significant additional gains can be made by using a more-suitable keyboard layout (e.g., the OPTI II layout is predicted to be 29.5% faster than Qwerty).
 7'15", 52Mb
7'15", 52Mb  7'37", 44Mb
7'37", 44Mb 

 7'16", 64Mb
7'16", 64Mb 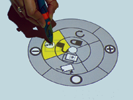 3'21", 15Mb
3'21", 15Mb Attribute gates are a new user interface element designed to address the problem of concurrently setting attributes and moving objects between territories on a digital tabletop. Motivated by the notion of task levels in activity theory, and crossing interfaces, attribute gates allow users to operationalize multiple subtasks in one smooth movement. We present two configurations of attribute gates; (1) grid gates which spatially distribute attribute values in a regular grid, and require users to draw trajectories through the attributes; (2) polar gates which distribute attribute values on segments of concentric rings, and require users to align segments when setting attribute combinations. The layout of both configurations was optimised based on targeting and steering laws derived from Fitts' Law. A study compared the use of attribute gates with traditional contextual menus. Users of attribute gates demonstrated both increased performance and higher mutual awareness.
 3'29", 21Mb
3'29", 21Mb  3'03", 16Mb
3'03", 16Mb  1'46", 5Mb
1'46", 5Mb 



