Keywords






 5'02", 23Mb
5'02", 23Mb 

Re-finding, a common Web task, is difficult when previously viewed information is modified, moved, or removed. For example, if a person finds a good result using the query "breast cancer treatments", she expects to be able to use the same query to locate the same result again. While re-finding could be supported by caching the original list, caching precludes the discovery of new information, such as, in this case, new treatment options. People often use search engines to simultaneously find and re-find information. The Re:Search Engine is designed to support both behaviors in dynamic environments like the Web by preserving only the memorable aspects of a result list. A study of result list memory shows that people forget a lot. The Re:Search Engine takes advantage of these memory lapses to include new results where old results have been forgotten.
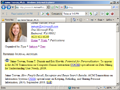
The Web is a dynamic information environment. Web content changes regularly and people revisit Web pages frequently. But the tools used to access the Web, including browsers and search engines, do little to explicitly support these dynamics. In this paper we present DiffIE, a browser plug-in that makes content change explicit in a simple and lightweight manner. DiffIE caches the pages a person visits and highlights how those pages have changed when the person returns to them. We describe how we built a stable, reliable, and usable system, including how we created compact, privacy-preserving page representations to support fast difference detection. Via a longitudinal user study, we explore how DiffIE changed the way people dealt with changing content. We find that much of its benefit came not from exposing expected change, but rather from drawing attention to unexpected change and helping people build a richer understanding of the Web content they frequent.
 7'23", 186Mb
7'23", 186Mb  4'40", 43Mb
4'40", 43Mb  4'20", 50Mb
4'20", 50Mb 
 4'18", 74Mb
4'18", 74Mb  6'10", 25Mb
6'10", 25Mb 

 5'14", 70Mb
5'14", 70Mb 
 7'23", 186Mb
7'23", 186Mb  3'03", 30Mb
3'03", 30Mb  4'22", 55Mb
4'22", 55Mb  6'56", 21Mb
6'56", 21Mb 





 7'39", 55Mb 7'23", 186Mb 4'22", 55Mb
7'39", 55Mb 7'23", 186Mb 4'22", 55Mb  7'40", 111Mb
7'40", 111Mb 
 5'12", 81Mb
5'12", 81Mb 
 8'09", 138Mb
8'09", 138Mb  2'01", 24Mb
2'01", 24Mb  3'09", 20Mb
3'09", 20Mb 

 7'36", 42Mb
7'36", 42Mb  3'56", 15Mb
3'56", 15Mb 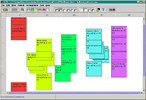

 57", 2Mb
57", 2Mb  2'54", 13Mb
2'54", 13Mb Temporal events, while often discrete, also have interesting relationships within and across times: larger events are often collections of smaller more discrete events (battles within wars; artists' works within a form); events at one point also have correlations with events at other points (a play written in one period is related to its performance over a period of time). Most temporal visualisations, however, only represent discrete data points or single data types along a single timeline: this event started here and ended there; this work was published at this time; this tag was popular for this period. In order to represent richer, faceted attributes of temporal events, we present Continuum. Continuum enables hierarchical relationships in temporal data to be represented and explored; it enables relationships between events across periods to be expressed, and in particular it enables user-determined control over the level of detail of any facet of interest so that the person using the system can determine a focus point, no matter the level of zoom over the temporal space. We present the factors motivating our approach, our evaluation and implementation of this new visualisation which makes it easy for anyone to apply this interface to rich, large-scale datasets with temporal data.
 2'57", 43Mb
2'57", 43Mb 
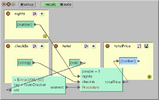
Webmail clients provide millions of end users with convenient and ubiquitous access to electronic mail - the most successful collaboration tool ever. Web email clients are also the platform of choice for recent innovations on electronic mail and for integration of related information services into email. In the enterprise, however, webmail applications have been relegated to being a supplemental tool for mail access from home or while on the road. In this paper, we draw on recent research in the area of electronic mail to understand usage models and performance requirements for enterprise email applications. We then present an innovative architecture for a webmail client. By leveraging recent advances in web browser technology, we show that webmail clients can offer performance and responsiveness that rivals a desktop application while still retaining all the advantages of a browser based client.
 2'27", 13Mb
2'27", 13Mb Information cannot be found if it is not recorded. Existing rich graphical application approaches interfere with user input in many ways, forcing complex interactions to enter simple information, requiring complex cognition to decide where the data should be stored, and limiting the kind of information that can be entered to what can fit into specific applications' data models. Freeform text entry suffers from none of these limitations but produces data that is hard to retrieve or visualize. We describe the design and implementation of Jourknow, a system that aims to bridge these two modalities, supporting lightweight text entry and weightless context capture that produces enough structure to support rich interactive presentation and retrieval of the arbitrary information entered.
2'27", 13Mb Information cannot be found if it is not recorded. Existing rich graphical application approaches interfere with user input in many ways, forcing complex interactions to enter simple information, requiring complex cognition to decide where the data should be stored, and limiting the kind of information that can be entered to what can fit into specific applications' data models. Freeform text entry suffers from none of these limitations but produces data that is hard to retrieve or visualize. We describe the design and implementation of Jourknow, a system that aims to bridge these two modalities, supporting lightweight text entry and weightless context capture that produces enough structure to support rich interactive presentation and retrieval of the arbitrary information entered.
 5'37", 62Mb
5'37", 62Mb 


